
Wo liegt die größte Herausforderung beim Umgang mit Legacy Code?
Über Twitter habe ich kürzlich diese Frage zu Legacy Code gestellt:

Nun ist Twitter bekanntermaßen darauf ausgelegt, nur knappe Antworten zu geben. Da jedoch mehr als ein Dutzend Antworten eingetroffen sind, will ich hier berichten, wo Entwickler Herausforderungen beim Umgang mit Legacy Code sehen. Die „Umfrage“ ist weit entfernt davon, repräsentativ zu sein. Ich glaube, die Antworten weisen dennoch auf die typischen Legacy Code Herausforderungen hin. Sollte Ihre persönliche Herausforderung nicht genannt sein, freue ich mich über Ihren Kommentar!
Automatisierte Tests
Die folgenden Antworten beziehen sich auf das Thema Tests:
- Fehlende Testabdeckung
- Regressionsbugs
- Das er genau das tut, was er vorher tat.
- definitiv dabei, die bestehende Funktionalität nicht zu zerstören
- Keine/Kaum Tests
- Üblicherweise bei den fehlenden Tests. Häufig meine ich, dass es ein riesiger Aufwand ist. Ohne scheint es zu unsicher.
- Für Legacy Code fehlende Tests anzubringen.
- Tests quasi unmöglich (techn., zeitl.)
Automatisierte Tests im Nachhinein zu ergänzen, ist für viele Entwickler eine Herausforderung. Das erlebe ich in meinen Trainings immer wieder. Insbesondere Abhängigkeiten der zu testenden Funktionseinheit zu weiteren Funktionseinheiten erschweren das Testen. Kleine isolierte und fokussierte Tests sind damit oft nicht möglich. Bezogen auf das gesamte Softwareprojekt entsteht die „Eistüte“ (s.u.) als Antipattern.
Die Anzahl der automatisierten Tests aus den beiden Kategorien Integrationstests und Unittests soll eigentlich so verteilt sein, wie in der folgenden Pyramide zu sehen ist. An der Basis viele Unittests, mit denen die Details der Domänenlogik überprüft werden. An der Oberfläche wenige Integrationstests, mit denen sichergestellt wird, dass die isoliert getesteten Funktionseinheiten wie geplant zusammenspielen.

Häufig kommt es in Legacy Systemen jedoch zu einer Umkehrung der Verhältnisse: viele Integrationstests, wenige Unittests.
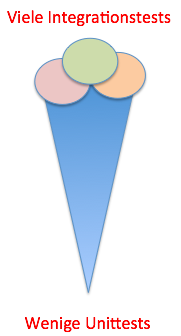
Dieses Antipattern führt dazu, dass die Tests insgesamt wenig aussagekräftig sind. Bei einem Fehler, der durch eine Änderung am Code entstanden ist, schlagen oft mehrere Integrationstests fehl. Da es kaum Unittests gibt, bleiben die wenigen, die es gibt, häufig grün. Dadurch ist zwar klar, dass etwas kaputt gegangen ist, aber es ist aufwändig, die eigentliche Ursache zu finden. Bei der empfohlenen Verteilung der Testanzahl würde im Fehlerfall ein einzelner Unittest anzeigen, wo genau das Problem liegt.
Auf der grünen Wiese helfen Empfehlungen wie, die Abhängigkeiten zu vermeiden, test-first zu implementieren, Aspekte zu trennen, meist weiter. Im Brownfield, auch Legacy Code genannt, sind die Hinweise auf Prinzipien genauso richtig, nur ist die Umsetzung ungleich schwieriger. Ich werde mich hier bei refactoring-legacy-code.net in nächster Zeit mit dem Thema auseinandersetzen und Tipps geben, wie in Legacy Code automatisierte Tests ergänzt werden können.
Den Code verstehen und ein Modell aufbauen
Nach wie vor trennen Teams die Phasen Entwurf und Umsetzung zu wenig. Nach der Analyse der Anforderungen wird gleich los codiert, statt zunächst eine Lösung für das Problem zu entwerfen. Daraus resultieren dann Softwaresysteme, bei denen das Modell, eine abstraktere Form der Lösung, nur im Code existiert. Die ursprünglichen Ideen aus dem Code zu extrahieren gleicht der Arbeit eines Archäologen. Die Antworten bei Twitter auf die Frage, wo die größte Herausforderung bei Legacy Code liegt:
- Soll-Funktionalität unbekannt
- Die Impl.idee zu verstehen, das Gedankenmodell der Impl. zu restaurieren, Methoden den richtigen Abstraktionsebenen zuzuordnen
- Jemand zu finden, der die Problem-Domäne mit Ihren über die Jahre entwickelten Edge-Cases versteht.
- Abwärtskomp.
Durch den fehlenden Entwurf bleibt nur der Code als Informationsquelle, um daraus abzuleiten, wie die Lösung des Problem eigentlich aussieht. Wenn dann noch die ursprünglichen Anforderungen nirgendwo dokumentiert sind, bleibt auch für diesen Teil nur der Code. So wird es schwer, neue Anforderungen in die Codebasis einzubringen, da jedes mal herausgefunden werden muss, wie die Lösung eigentlich funktioniert. Im Anschluss muss dann in eine undurchsichtige Lösung eine Ergänzung eingebracht werden.
Jedes Mal, wenn Sie sich mit dem Code beschäftigen, ihn lesen und analysieren, ihn im Debugger durchlaufen, gewinnen Sie wichtige Erkenntnisse über den Code. Wie sichern Sie diese Erkenntnisse? Mühsam führen Sie den Code Schritt für Schritt aus, um herauszufinden, auf welche Weise ein bestimmtes Feature implementiert ist. Nachdem Sie das erforscht und den Bug behoben haben, sind Sie vermutlich froh, dass Sie sich nun wieder anderen Aufgaben zuwenden können. Die mühsam erarbeiteten Erkenntnisse über einen kleinen Ausschnitt der Codebasis gehen verloren, da sie nur in Ihrem Kopf vorliegen. Abhilfe können Refactorings schaffen. Und hier meine ich nicht die sogenannten komplexen Refactorings, sondern die einfachen Refactorings, die Sie vollständig mit einem Refactoring Werkzeug wie Visual Studio oder JetBrains ReSharper durchführen können. Ich habe dazu einige Blogbeiträge geschrieben.
Organisatorische Herausforderungen
Eine Antwort bezieht sich auf Herausforderungen innerhalb der Organisation eines Softwareentwicklungsprojekts:
- Den/die Verantwortlichen von der Notwendigkeit zu überzeugen.
Der Product Owner erwartet, dass wir als Entwickler wandelbaren Code schreiben. Völlig zu Recht geht er davon aus, dass wir nach den Regeln der Kunst arbeiten (das könnten bspw. die Werte, Prinzipien und Praktiken der Clean Code Developer Initiative sein). Wandelbarkeit stellt für den Auftraggeber Investitionsschutz dar. Jemand nimmt viel Geld in die Hand und möchte dafür eine Codebasis erhalten, die langfristig verändert und erweitert werden kann. Um Wandelbarkeit herzustellen, müssen Prinzipien eingehalten werden:
- Aspekte müssen klar getrennt werden
- Abhängigkeiten müssen als eigener Aspekt betrachtet und isoliert werden
Wenn diese beiden Prinzipien beachtet werden, entsteht eine Modulstruktur, die gut testbar und leicht verständlich ist. Damit ist die Wandelbarkeit der Software hergestellt. Dem Product Owner können dann über Jahre hinweg neue Featurewünsche erfüllt werden, ohne dass der damit verbundene Aufwand plötzlich dramatisch ansteigt.
Die Realität sieht allerdings so aus, dass die Wandelbarkeit der Codebasis eben nicht gegeben ist. Diese müsste eigentlich durch einen regelmäßigen Mehraufwand wieder hergestellt werden. Wird dieser Aufwand immer wieder verschoben, wird das Problem größer und größer. Es gilt hier, die Pfadfinderregel anzuwenden und den Code ständig zu verbessern, statt nur Features rauszuhauen.
Auf die Wandelbarkeit zu verzichten, bedeutet den Investitionsschutz zu vernachlässigen. Dadurch türmt sich wie bei einem Kredit eine Schuld auf, die abgetragen werden muss. Geschieht dies nicht, werden neue Features, Änderungen und Bugfixes immer teurer.
Psychologische Hürden
- „Überwindung“ 😉
- anzufangen
- Frust
Vielfach haben Entwickler längst die Erkenntnis gewonnen, dass die Codebasis saniert werden müsste. Wird ihnen dazu keine Zeit eingeräumt bzw. schaffen es die Entwickler nicht, sich diese Zeit zu nehmen, entsteht Frust. Gegen besseres Wissen zu handeln, fühlt sich nicht gut an. Oft sind es mangelnde Kenntnisse, die eine zügige Verbesserung der Situation verhindern. Wer nicht gelernt hat, „auf der grünen Wiese“ Tests zu schreiben, wird es im „Matschfeld“ des Legacy Code erst recht nicht beherrschen. Es geht hier nicht darum, einen Schuldigen zu finden, sondern die Situation anzuerkennen und durch gemeinsame Reflexion immer wieder herauszuarbeiten, wo die Probleme liegen.
Technische Herausforderungen
- Reflection-bedingte Fehlerquellen
- Migration
In manchen Codebasen mehr als in anderen, gibt es technische Herausforderungen. Eine Software die Maschinen ansteuert hat in der Regel zeitkritische Bereiche, in denen es um hohe Performance geht. Die Lesbarkeit des Codes muss da ggf. an zweiter Stelle stehen. Oder vielleicht ist das Softwaresystem sehr flexibel und vom Kunden anpassbar, dann kommt vielleicht an vielen Stellen Reflection zum Einsatz. In der Regel sind diese speziellen Features, die im Kern das Alleinstellungsmerkmal der Software ausmachen, nicht isoliert und von anderen Features getrennt realisiert, sondern wild über die Codebasis verteilt. Damit entstehen technische Herausforderungen, die eine Sanierung aufwändig machen.
Fazit
Refactoring von Legacy Code hin zu Clean Code ist für viele Teams eine große Herausforderung. Auf lange Sicht bleibt den Entwicklern nichts anderes übrig, als sich dieser Herausforderung zu stellen. Geschieht dies nicht, droht in letzter Konsequenz der Untergang des Unternehmens. Die Wandelbarkeit der Software muss erhalten bleiben bzw. hergestellt werden. Dies stellt den Investitionsschutz für den Auftraggeber dar.
Was sind Ihre Herausforderungen beim Umgang mit Legacy Code? Nehmen Sie an meiner Umfrage teil!